 ������w
������w
�l�H���H�w�����Z���^�[
�f�W�^�����l�H�w��������
���R�@�W
|
1. �͂��߂�
�@Varian��Lyman�́C1999�N�ɐ��ݏo���ꂽ����1�G�N�T�o�C�g�ƌ��ς����Ă���[1]�D�������C���ۂɐ��ݏo���ꂽ�f�[�^�͂���ȏ�̂��̂ł������Ɨ\������Ă���D�����āC���̌�̂T�N�Ԃ̃C���^�[�l�b�g�̃u���[�h�o���h���C�X�l��1�e���o�C�g�ȏ�̋L���e�ʂ���n�߂��n�[�h�f�B�X�N���u�̑�e�ʉ��́C�c��ȗʂ̃f�[�^�̍L�敪�U�����������Ă���D�}1�ɂ����āC�f�[�^�̑��������ƂƂ��ɖ͎��I�ɕ\�����D�����ɂ���āC�f�[�^�͎��o���ɓZ�߂��i���ӂȂ��̂����p����j�C��U�̓f�[�^�̑�����}���邱�Ƃɐ����������Ɏv�����D�������Ȃ���C�����I�ɔh������f�[�^�C�z�ɕ\���ł��Ȃ��f�[�^�C���ݏo���ꂽ���o��g�̑�����������ƁC�����ł��Ȃ��قǂ̃f�[�^�E��w�����I�ɒ~�ς������Ă���D���̏�Ŕj���邽�߂ɁC�l�X�ȃf�[�^�}�C�j���O��@��L�敪�U�^�̏��Ǘ��V�X�e������Ă���C�������̂��̂����ۂɗ��p�����悤�ɂȂ�D�����āC���̎w�����I�ȑ�������Q���I���̂ɓ]����Ƃ����w�E���Ȃ���͂��߂Ă���i�}�P�E��j�D�������C����̓����͊y�ώ��ł�����̂ł͂Ȃ��D���Ƃ��C�ꈬ��̐��Ƃ��m�����W�Ă������Ƃ��Ă��C�m���n���̉\���̂���f�[�^���命���̌l�̑��Ɏc����邱�Ƃ������ł��낤�D�ۑ�́C�l�̔\�͍��ɂ��f�[�^�E���E�m���̏W��x�̈Ⴂ���ǂ̂悤�Ɉ������ł���D
�@���̏��������ꍇ�ɂ����Ă��C�e�L�X�g�f�[�^�C������f���f�[�^�������l�f�[�^�ɔ�d���������f�[�^���͂Ƃ����Ⴂ�͂��邪�C���l�Ƀf�[�^�̑�K�͉��C���U�������ɂȂ��Ă���D�����ɂ�����f�[�^�擾�Z�p�́C�_����ʁC�����ċ�ԂւƐi�W���C�v�Z�ɂ����Ă͎���Ԃ̍��𑜉����i�݁C�p�[�\�i���R���s���[�^�̔���I�Ȑ��\����ɂ���ăf�[�^�͌l�̑��ɒ~�����邱�Ƃ����������߂ł���D���̂悤�ȏ̒��ŗ��̏��ɂ�����f�[�^�}�C�j���O�Z�p�̍��x���p�̕K�v�������܂��Ă���D
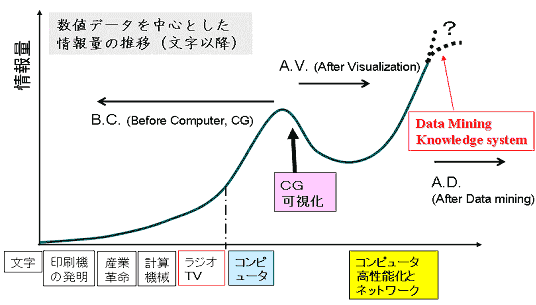
�}�P�D���̔������Ə��ʂ̐���
2. �f�[�^�}�C�j���O��@�ƒm�������v���Z�X
�@�J��Ԃ��悤�ł��邪�CCFD���ɂ���ƁC80�N��̓X�[�p�[�R���s���[�^�̔��W�����܂��đ�ʂɓf���o���ꂽ�f�[�^�ł͂��������C�f�[�^�̉��߂₻��Ɋ�Â�������i���邢�̓f�[�^�̍č\���j�͗e�Ղł���ƍl�����C�K�v�ȕ���������苎��C��l�̌����҂ł������Ȃ��قǂ̃f�[�^�͎c��Ȃ����낤�Ƃ����������������D�Ƃ��낪�C���l���̐M�����̖��𗝘_�I�ɉ������邱�Ƃ͓���C��ɍX�Ȃ鍂�𑜓x�v�Z���K�v�Ƃ���C��ʂ̃f�[�^�����ݏo���ꑱ���Ă���D���ʂƂ��ėL�ӂȕ����Ɩ��ӂȕ������邱�Ƃ������Ȃ��Ă���̂�����ł���D�܂��C�����ɂ����Ă��CPIV�Ȃǂ̍L�͈͂̋�ԏ����������@�����W���C���l�̏�����D���̂悤�ɑ��푽�l�ȑ�K�̓f�[�^�����U���đ��݂��C���̏����̖�肪�N���[�Y�A�b�v����Ă���̂ł���D
�@���̏����ʂ���C���̂S�̂��̂ɂȂ�D
�� �v���v���Z�X�Ɋ֘A������i���ݒ�ɗ��ޏ��F�`��C�����E�v�p�����[�^���j
�� �����v���Z�X�Ɋ֘A������i���l�v�Z�C�������u�C�ϑ����u�j
�� �|�X�g�v���Z�X�Ɋ֘A������i������j
�� ���p�C�W�J�C�t�B�[�h�o�b�N�Ɋ֘A������i���̌��ۂɊւ�����C�v���C�����j
���ꂼ��͓Ɨ����Ă���킯�ł͂Ȃ��C����ɂ͍ו������������ǂ��ꍇ������D�����Ă��̂悤�ɕ��ނ����̂́C�f�[�^�}�C�j���O�ɂ����ď��̍\�����ƊK�w�����d�v�Ȗ����𐬂��Ă��邽�߂ł���D�f�[�^�}�C�j���O�́C�\�����ƊK�w���̉ߒ��C�y�т����̉ߒ��̌�ɐ�����f�[�^�C���ɑ��Č��͂�����D
�@���āC���ڂ���邱�Ƃ������Ȃ����f�[�^�}�C�j���O�ł͂��邪�C�f�[�^�}�C�j���O��@�̑����́C���v��́i���邢�̓f�[�^���́j�ɂ����ėp�������@�Ɠ����ł���C�m�����v�w���x�[�X�ɔ��W���Ă���D���̉�͂ɂ����ẮC�����܂ł��Ȃ������̕���C�f�[�^�����𒆐S�ɂ��ē��v��̗͂��p�E���p�͐���ł������D����ɂ���ē���ꂽ�m���������D�ł́C�]���̓��v��͂Ƃ̑傫�ȈႢ�͂Ȃ낤���H �����̋��ȏ��ł̓f�[�^�̑�K�͉��ƃA�N�Z�X�̗e�Ղ��������C��W�c�ɑ��钼�ړI�ȃf�[�^�̕��́i�W�{���o���s��Ȃ��Ƃ����Ӗ��j������Ó����icross validation�j�ɑ��ď\���ȃf�[�^�����݂��邱�Ƃ��������Ă���[2][3][4]�D�܂��C���v�I����_�ɑ������@�Ȃǂ̑��ݗ��R���Ȃ��Ȃ�C���̂悤�ȓ����ɈႢ������Ƃ����咣������D����ɁC"�w�K"�Ƃ����L�[���[�h����C"�j���[�����l�b�g���[�N"���Ⴂ�̈�Ƃ��č̂�グ�邱�Ƃ������D�����Ă��̂悤�ɈႢ���ۂ�������K�v�͂Ȃ��悤�Ɏv���邪�C�����Č����C�f�[�^�}�C�j���O���m�������v���Z�X�܂ł��X�R�[�v�Ɋ܂߂Ă��邱�Ƃ�����ł��낤�D�܂�C�m���n�o�ߒ���m�������ߒ��ւ̓W�J�����Ȃ̂ł���D���̂��߁C�f�[�^�}�C�j���O�Ƃ��������ɂ����āC�������̒m�������v���Z�X����Ă���Ă���D�����������DFayyad��[5]�́C
�i�@�jData����Target Data�֕ϊ�����
�i�A�jPreprocessed Data����Transformed Data�֕ϊ�����
�i�B�jTransformed Data���N���X�^������Ȃǂ��ăp�^�[���iPatterns�j�𒊏o����
�i�C�jPatterns����m���iKnowledge�j��n�o����
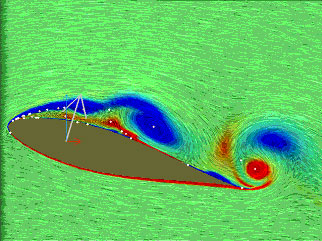
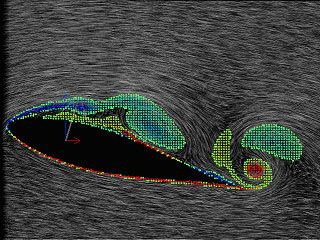
�Ƃ����悤�Ȓm�������̃v���Z�X���Ă����D�f�[�^�}�C�j���O�Ɠ��v��͂Ƃ̈Ⴂ�̈���m�������v���Z�X�܂ł�����ɓ���邱�ƂȂ̂ŁC���̏����l�����ł����̓_�ɗ��ӂ���ƐV���ȓW�J�����҂ł���D���҂��Fayyad��̃v���Z�X���Q�\���̒��o�ߒ��ɓK�p���C�Q�\���̕ω��ƕ��̂ɓ������̗͂̕��͂ɗ��p�����i�}2�C�}3�j[6][7]�D���̌��ʁC�m�������v���Z�X�̑����͐l�Ԃ̎v�l�p�^�[�����`�����������̂ł���C��Ǝ菇�̊m��ɑ��Ă͗L�p�ł��邱�Ƃ����o�����Ƃ��ł����D
|
�@ |
|
|
(a)
(�N���b�N����ƍĐ��@mpg:1MB)
|
|
(b)
(�N���b�N����ƍĐ��@mpg: 3.8MB)
|
| �}2. �Q�x���z����Q�v�f�ցD���}(a)�̓s�N�Z���I���@[8]�ɂ���ĉ����������x��ɉQ�x���z�i�F�����v���̑��x���U�N����Q�x�C�ԐF�͔����v���̂��̂������j���d�˂����̂ł���D�E�}(b)�̓_��̂��͉̂Q�x���z�ɂ��ƂÂ��Ē��o�����Q�_�v�f�������Ă���D |
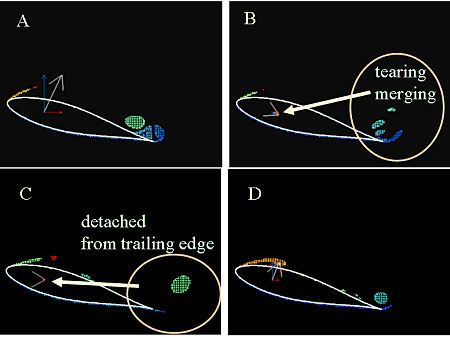
�}3. ���o�Q�v�f�ɂ��ÓI�����̐���
3. ������
�@�f�[�^�̑�K�͉��́C���̉^���̔���`�����ۂ������C�]���I�ȕ��͎�@�̌��E�������Ă���D�����āC��Ƃ��Ĕ���`���ɋN������傫�ȃp�����[�^��Ԃ̒T���ƁC����ꂽ���ʂ̉��߂���m�������֎���ߒ��ɂ����ăf�[�^�}�C�j���O��K�v�Ƃ��Ă���D�����ŁC���{�@�B�w��犧�s�\��̃t���[�h�C���t�H�}�e�B�b�N[9]�ł́C�Q�\��������̈�Ƃ����ꍇ�̒m�������v���Z�X�C�m�I�����헪�C�m���x�[�X�̗��p�C�p�����[�^���E�V�X�e���Ƃ����������̎��ጤ�����Љ�C�����̒��ŁC�f�[�^�}�C�j���O��@�̓K�p�@�Ƃ��ꂪ�ǂ̂悤�ɒm�������ɗ��p�ł���̂��ɂ��Đ������邱�Ƃɂ����D�������Ȃ���C���݂̃f�[�^�}�C�j���O��@�ɑ��Ė��\�ł���Ƃ��C�m���������I�ɔ������Ă����Ƃ����l���͎̂Ă�K�v������D�u�悭�悭�l����Ƃ������v�C�u�������Ă������Ƃ��������v�C���邢�́u�⏕�I�ȏ������I�ɐ������Ă����v�̂悤�Ȏ�Ƃ��Ďx�����������̂ƍl���������悢�D���Ƀh���C���i�̈�C���邢�͕���j�̏���m���̖������傫���D���̂��߁C��ʓI�ȃf�[�^�}�C�j���O�����̂܂ܗ��p����Ƃ������́C�����Ƀh���C���̒m�����g���������ƂȂ�̂ł���D����Z�p���i�Ƃ��Ă����̍H�w�ŗL�̌����̕K�v���͂܂��܂��傫���Ȃ邾�낤�D�����ɂ����̂̂������낳������D
�Q�ƕ���
[1] Lyman,P. and Varian H.R.:How much information�FSee http://www.sims.berkeley.edu/research/projects/how-much-info/
[2] Pieter Adriaans, Dolf Zntinge���C�R�{�p�q�C�~�����i��F�f�[�^�}�C�j���O�C�����o�ŁC1998
[3] �L�c�G���F���z���@�蓖�Ă铝�v�w�C�u���[�o�b�N�XB-1325�C�u�k�ЁC2001
[4] �}�C�P��J.A.�x���[�C�S�[�h���E���m�t�F�f�[�^�}�C�j���O��@�C�C�����C1999
[5] Fayyad,U., Piatetsky-Shapiro,G. and Smyth, P., AI magazine vol.17, 1996, pp.37-54.
[6] ���R�@�W�C��a�T�K�C�q��F���Z�p���������ʎ���SP-46�C2000�Cpp.249-254.
[7] ���R�@�W�C��a�T�K�C���{���D�w��_���W��188���CNov. 2000�Cpp.23-31.
[8] Shirayama S. and Ohta,T., Journal of Visualization Vol.4, No.2 (2001), pp.185-196.
[9] ������F�t���[�h�C���t�H�}�e�B�b�N�C���{�@�B�w��ҁC�Z�o��(��), 2004�����\��
|
